
))
Live at “Growing your Workforce”
Manage episode 453239240 series 2805499
Contenu fourni par Mean, Median, and Moose. Tout le contenu du podcast, y compris les épisodes, les graphiques et les descriptions de podcast, est téléchargé et fourni directement par Mean, Median, and Moose ou son partenaire de plateforme de podcast. Si vous pensez que quelqu'un utilise votre œuvre protégée sans votre autorisation, vous pouvez suivre le processus décrit ici https://fr.player.fm/legal.
This episode is special as it’s our first live recording! Time was limited so you may hear us speak quickly and have less banter, but we hope you enjoy the episode anyway.
Job post vector embeddings (John)
This is a small exploration of vector embedding. These are components, primarily related to the input for training and using LLMs. They also have a lot of other interesting use cases in the area of search.

We’re going to use some job posting data provided to use by the hosts of “Grow Your Workforce”, the good people at “Workforce Windsor Essex”. We got the raw data that drove their job board and used some scripts to scrape and extract the job posting data from 1,200 job postings in the Windsor-Essex area.


Next we translated this into a vector embedding, which is a 2,048 number description of the words and their positions for the job posting. In this way, the job posting becomes a point in 2,048 dimensional space. We used a well known LLM model to do this, but there are likely more appropriate models for this use case.

This is Mean, Median, and Moose which means it doesn’t exist if it’s not in a chart. Unfortunately, data in 2,048 space is very difficult to visualize. Luckily there are techniques to convert this large dimensional data into a smaller number of dimensions. One such technique is called t-SNE. We used to to convert our vector embeddings to 2D space:

Now we can chart it:

You can see that the data is clumped together in clusters. We set it up so that you can hover over a point to understand what job posting is at that point. When you do so, you’ll see that related jobs are close together. You can do this yourself at the interactive version of the chart here.

You can compare this “automatic clustering” by the model with the manual NOC 2015 code put into the data set by WFWE in this diagram below:

You can see the clusters of jobs do follow similarly colored clusters of jobs. You can imagine how one might compute the vector embedding of a search term to find the closest jobs to that term. Or compute the vector embedding of one job to find similar jobs. Or compute the vector embedding of a resume to see job postings that contain similar lists of skills. All of this is a kind of “semantic search” and vectors are a common way to implement them. Add int the rest of the transformer to generate text based on the vector embeddings and you have an LLM.
The use of emojis in workplace communication (Katie)
So I used to work at Workforce WindsorEssex, and I mulled over updating one of my old reports, but I figured, why not explore something we all see everyday but probably haven’t seen much data on? Emojis at work. If you’ve emailed or messaged with me, you know I’m a huge fan of using emojis at work.
The earliest Canadian data I could find that specifically focused on using emojis at work was from 2016 when OfficeTeam, a Robert Half Canadian staffing firm, conducted a survey on using emojis at work, garnering responses from more than 300 senior managers at Canadian companies and more than 400 Canadian workers employed in office environments. They asked respondents to choose 1 of 4 statements they most identified with regarding emoji use in work communications. The result? A resounding thumbs down from the senior managers with 79% considering them unprofessional, but more of a shrug from the workers, with 36% using them often or in casual communications. Can we assume most senior managers were Gen X or Boomers, while more workers were Millennials? Probably, and you’ll see why this is important in just a minute.

Some of the more comprehensive data on emoji use in the workplace I found was American data from September 2024 when Mailsuite, an email tracking tool company, worked with the research consultancy Censuswide to survey 2013 American office workers about how they use and perceive emojis in work emails.
Mailsuite and Censuswide were kind enough to create beautiful data visualizations so I didn’t have to. Of 9 perceptions of emoji use, the top 4 respondent perceptions were positive, with email emoji use associated with being more friendly, having more personality, being more fun, and being more approachable. All 5 negative perceptions of emoji use, including being unprofessional, annoying, cringey, less competent, and less intelligent, ranked significantly lower.
Importantly, does why we use emojis match the increasingly positive perception of use? On the highly positive side for workplace culture, 56% of respondents incorporate emojis into emails to be friendly, 41% use emojis to soften communication, and 31% include them to show they are approachable. Then of course, 19% have succumbed to peer pressure and use them because other colleagues do, and there’s another 6% who are just being a little passive-aggressive.
Of course, Mailsuite also confirmed what we all could’ve guessed – emoji acceptability in work emails varies greatly by generation and situation, with Gen Z and Millennials by far leading the generation pack compared to Gen X and Boomers in finding it acceptable to use emojis in work emails to colleagues, customers, and managers and even in some stickier work scenarios like telling a colleague they’ve done something wrong.

So, what does more recent, though slightly less comprehensive, Canadian data say? The University of Ottawa’s School of Psychology seems particularly happy to support emoji research, with several studies published between 2019 and 2024. A 2021 UOttawa study on general emoji use found emojis convey information about the sender’s affect, senders that use positive emojis are perceived as being warmer, and emojis enhance comprehension of messages, with the study concluding support for the use of emojis to improve communication, express feelings, and make a positive impression during socially-driven digital interactions.
Olivier Langlois’ 2019 study that asked about emoji use in professional contexts found “positive” emojis were both acceptable and welcome in the workplace after some familiarity was established, while using “negative” emojis causes discomfort. Like the American study, he also found older people are significantly more resistant to and put off by emojis than young Millennials and Gen Z. Most interestingly, he notes, “This desire to break formality by using these digital images is found in the response of a 17-year-old participant who adds emojis to ‘lighten the tone of the conversation.’ A 21-year-old participant also wants to avoid frigidity by using emojis ‘to make the conversation more relaxed.’” UOttawa student Megan Leblanc’s 2023 study further confirmed the magnifying effect of emojis, finding that emojis “magnified both perceptions of agreeableness and perceptions of emotional state. Social context had no effect.” – meaning this finding applies in professional contexts too.
Another UOttawa Study from 2024, which was the first comprehensive investigation into intergenerational emoji use in adults over 60-years-old, found that older users are less likely to use emojis, use fewer emojis, and feel less comfortable in their ability to interpret emojis. The study suggests that it is important to promote the usage of emojis across all ages and specifically older adults as it could help facilitate intergenerational interactions.

So, based on all the data we just reviewed, I hope you can guess why you should care about emoji usage at work? Those who use emojis at work are, for the most part, and as long as they’re using positive emojis, trying to spread positivity and build strong work relationships, and this just happens to speed up workplace communications and enhance their effectiveness too. Most importantly, using emojis is a way to improve intergenerational text-based communication, which we all know has become incredibly important in this digital and multigenerational workplace! So fear not, Boomers and Gen X, embrace those emojis, and you might just find the younger generations embracing you a little more too.

Income Inequality and Market Income (Frazier)
Once again I return to income inequality data but as this is a workforce summit I am focusing on a specific type. Income inequality is tracked by the Gini-Coefficient/Index with a score of 0 being perfectly equal and all income being spread out evenly across a population while a score of 1 is perfectly unequal – one person holding all of the income.
In Canada we track income inequality in three forms – Total Income, After Tax Income and Market Income. Each of those forms are available in adjusted or unadjusted forms which group incomes by household (adjusted) or individually (unadjusted). For this I am largely talking about adjusted market incomes.
Using data from the T1 Taxfiler database we can see how Canada and Ontario have fared over time.
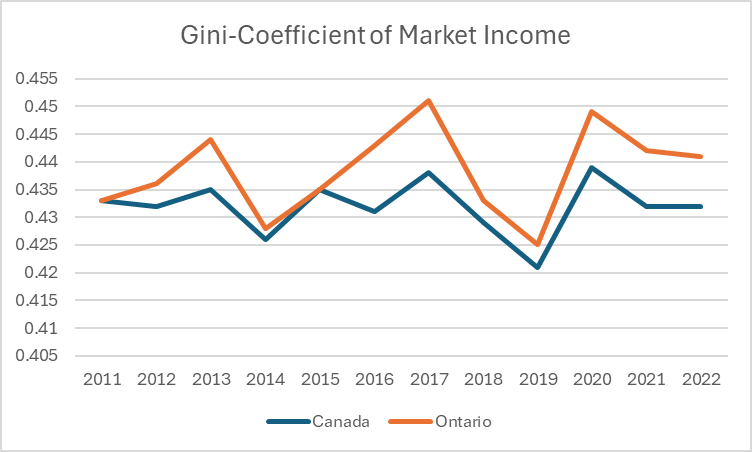
Nationally things have stayed about the same from a market income perspective whereas Ontario tends to be a few points above the national trend. To be honest, this is largely due to Toronto. When you put the other forms of inequality onto a chart you see similar trends overall at slightly lower levels – high 0.3 as government transfers offset some of the inequality in market incomes.
Now part of the problem with inequality data is that outside of the Census it is limited in scope and availability. But as I mentioned on the podcast before I have a specialized dataset that covers the last two censuses from Ontario!
Looking at a Census division level (region) we see the following trends.
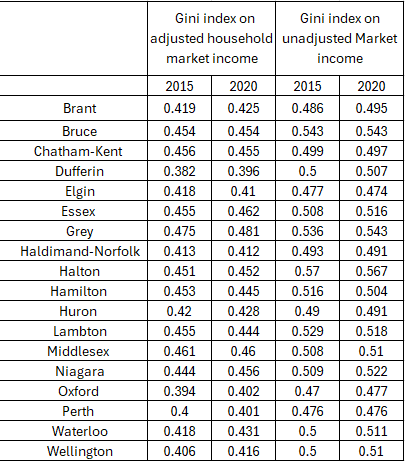
I find the difference between adjusted and unadjusted income as it shows how accounting for households as a unit vs individuals within the household separate as interesting. First and foremost across Ontario inequality in most regions went up between 2015-2020.
Dufferin, Waterloo and Niagara saw the largest increase in market income inequality increased the largest – likely having to do with some overflows from Toronto. In contrast, Lambton, Hamilton and Elgin saw their inequality in market income decline! Hamilton is the surprising one as I would assume Toronto overflows would impact it as well.
The difference between adjusted and unadjusted inequality is worth about 0.07 increase in inequality across these communities with the largest increases in Halton and Dufferin region and the smallest increases in Chatham-Kent and London-Middlesex. What you are seeing there is the gender and inter household income inequality play out.
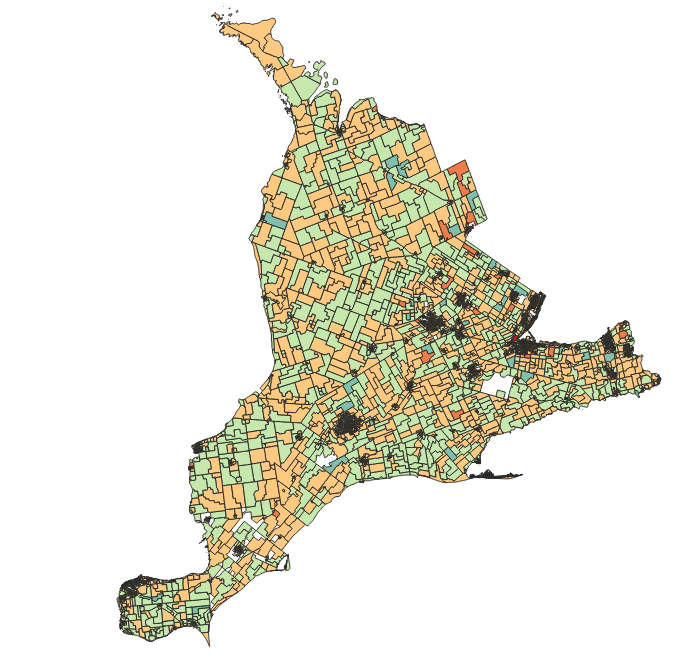
Although deeper analysis is likely needed why a particular DA became more or less equal at a glance, green areas saw income inequality decline, whereas the orange shaded saw income inequality increase.
Of the 6,904 Dissemination Areas (population ranges generally between 500-800 people) 4,099 saw the market income inequality increase – approximately 60% of DA representing approximately 2.7 million people – a population greater than all of the Atlantic Provinces.
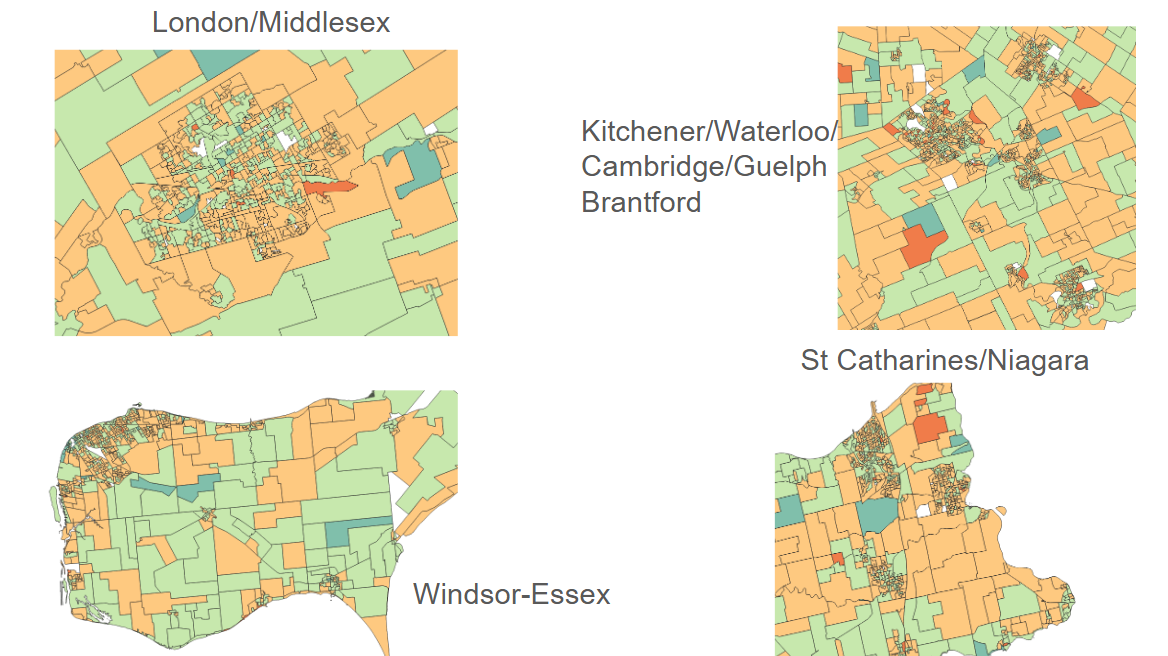
The interesting piece of this is that these maps compare pretty strongly to some historical data. These maps look alot like inequality data from rust belt US in 2010-14 period – the lead up to the first Trump Presidency.
Fortunately when we look at data from After-Tax Inequality we see better outcomes, but that data includes 1 time COVID supports which have now disappeared and if you recall from the first chart from a provincial level inequality has dipped a little bit since 2020, but is still up. Market incomes have likely adjusted as well as some people were laid off during the Census etc.
As someone who does work in community the feeling of being left behind, is palpable now.
So for our workforce planning people in the room, the question is, is a job a job anymore. Is a salary a salary? What is your role in ensuring that work is good paying, and has opportunity in your community and is not just driving inequality. Something to think about.
Job Benefit Extraction (Doug)
I used the same jobs data as John. Thanks, John for cleaning up all that data – it was really nice to work with.
In looking around at recent research in this space, I found a paper published in a journal called Applied and Computational Engineering by Jie Zhou and others. This paper demonstrates a method to use Large Language Models to extract structured data from free-text job postings. Zhou reported pretty impressive results, with a refined LLM prompt producing more accurate results than a more traditional dictionary method for data extraction.
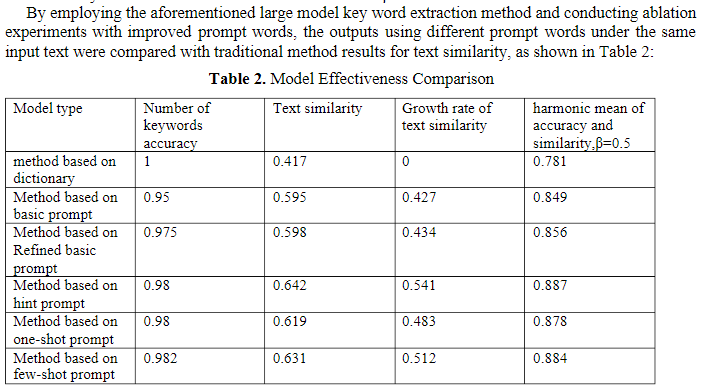
I wanted to see if I could get a similar level of accuracy with the Workforce job data, and I decided to focus on benefits, as a proxy for job quality.
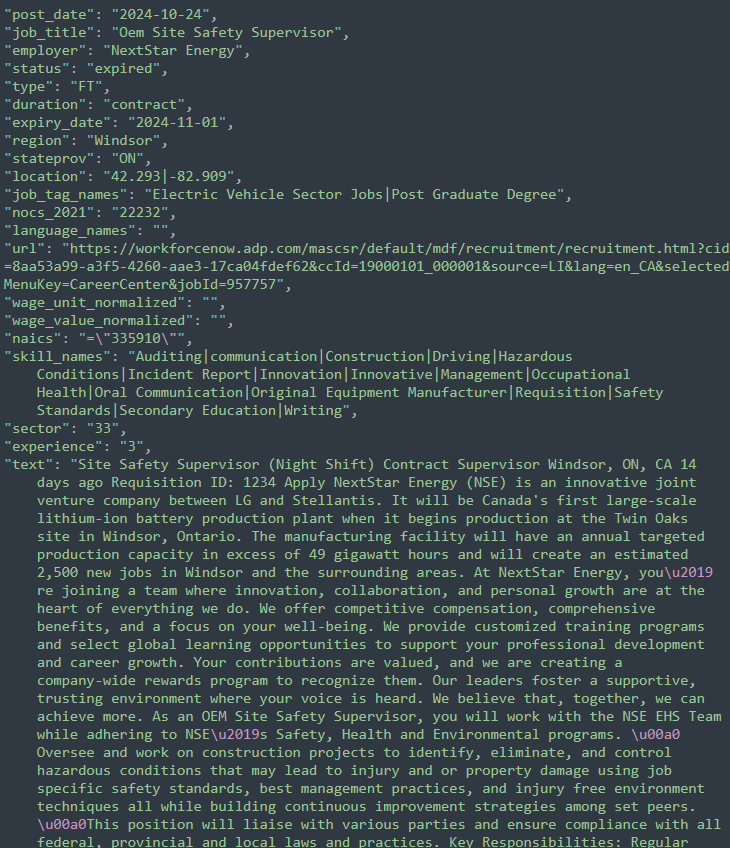
Here’s a sample record from the Workforce jobs data. It’s really nice, with lots of structured data for analysis. One thing that’s missing from the structured data is information about benefits, but employers often provide information about benefits in the text of the job posting. I hoped it was possible to enhance this data set with some information about benefits.
Zhou used a model called ChatGLM3 to process a data set of around 32 thousand jobs from a Chinese jobs database.
I wanted to compare different models’ performance, so I used Nebius, a company that provides a variety of services for people working with artificial intelligence applications. They’ve got an API for interacting with LLMs, and they offer a broad variety of models to interact with. I found the comparison tool in the API playground invaluable for comparing model performance.
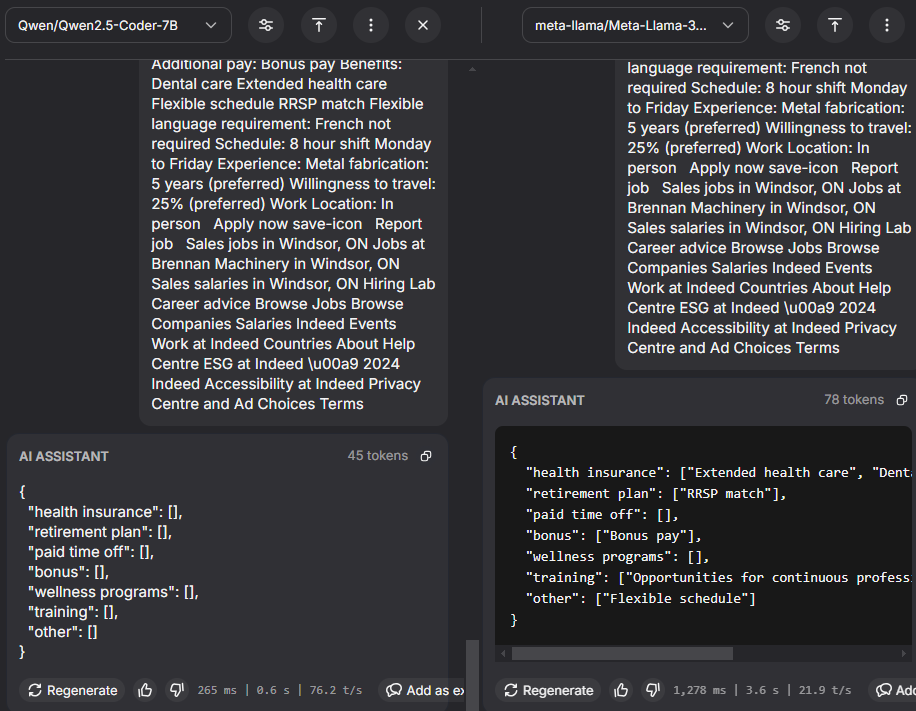
Different models have different capabilities, and are tuned for different functions. I worked through most of the list and found, unsurprisingly, that the flagship Meta open source model Meta-Llama-3.1-405B-instruct, offered the most reliable performance.
That name is a mouthful – breaking it down, I used Meta’s Llama 3.1 model, the version released in July of this year which has 405 billion parameters. The higher the number of parameters a model can adjust in training, the more complex and nuanced performance it is capable of. More parameters can also make a model slower and more costly to use.
In my testing, I found that most other models on offer had an error rate so high that it was observable in interactive tests. With more extensive prompt tuning, it is probably possible to use a cheaper model for this task.
It didn’t take long before I had a prompt that would reliably return an array of benefit strings for processing. I tried a lot of different versions of this prompt, but this was one of the last ones before I abandoned it. I choose this one because it shows the way I was trying to prompt the LLM to return more structured data. A persistent problem was that it would not reliably categorize benefits based on this prompt, preferring to spit out strings pulled directly from the job posting.

Unfortunately, I found that extracting benefit strings alone was too unreliable for a couple of reasons. There are a lot of questionable perks – low- or no-value items describing work culture or attitude – identified in job postings. I didn’t want to measure the perkiness level of job postings so I needed to find another solution. In addition, there was too much variety and at the same time too much similarity in benefit strings. I used k-means analysis to get a sense of the data, but this structure was pretty resistant to analysis.
Eventually, I came up with a prompt that would return usable data.
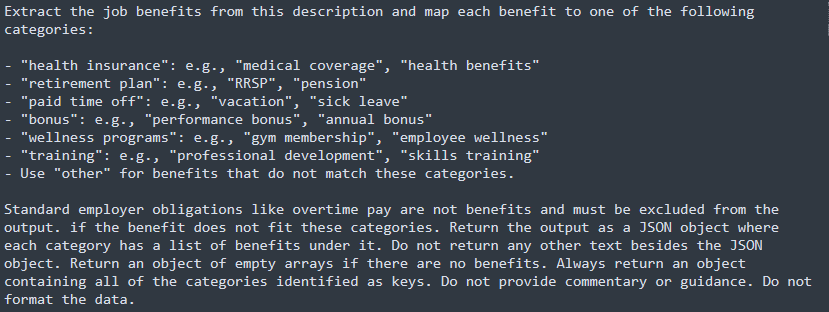
The main breakthrough was in providing a list of categories of benefit. This hint was what the machine needed. The data structure it returns is highly useful as it provides a listing of the benefit strings under each category, so we get the raw data plus the categorical assignments. This allows for a pretty solid evaluation of the quality of LLM output, and a few different paths for analysis.
Remember those cheery but non-material “benefits” I mentioned earlier? That’s what the “other” category is for. It’s the garbage can for dodgy benefits – The LLM rolls up most of that stuff into the “other” category, which I then throw away before analysis.
The model I used costs $1 per thousand input tokens, and $3 per thousand output tokens. Tokens are the basic building block of LLM analysis, typically representing about four characters of text. All-in I spent about $15 on machine time to try out this method. The cost of a single run on the whole body of job postings is a little less than $4.
Combining the data returned with the original job posting gives us a rich data set with plenty of features to use in analysis. A lot more can be done to refine the prompt and the resulting dataset, but this prompt is solid enough for a proof-of-concept. It’s pretty accurate – I had an intern check a sampling of 100 job posts, which were 100% accurate. The LLM did not hallucinate any benefit strings and correctly categorized the benefits in all cases.
I tried a few ways of visualizing this data and the heatmap is the most useful. Here’s the benefits data summarized by two-digit NOC. “NOC” stands for National Occupation Classification, and it’s a widely-used taxonomy for categorizing jobs. Workforce includes NOC data in the jobs dataset.
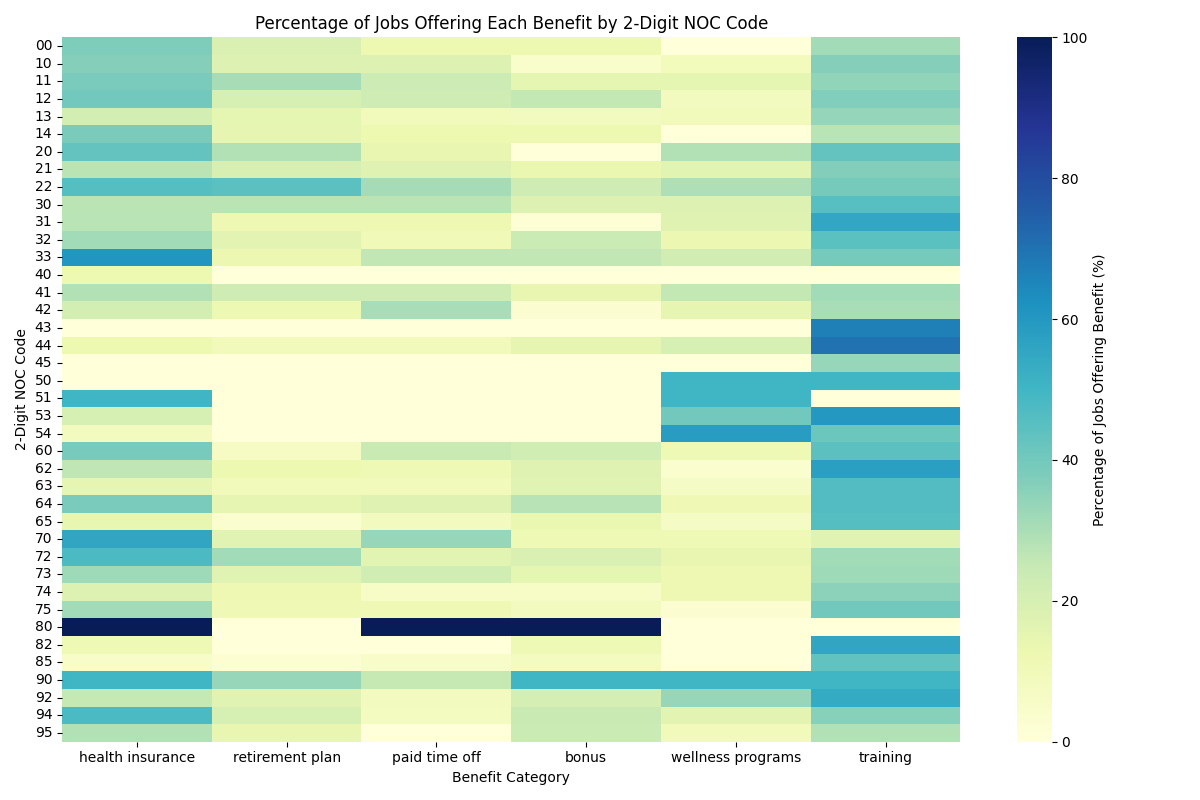
A few highlights to mention here – 80 is the code for middle management occupations in natural resources extraction and agriculture, demonstrating the limitations of this particular data set. That’s one job at AMCO produce. Looks like they’ve got a nice benefits offering. 43, 44, and 45 are notable for how rare material benefits are. Those are “occupations in education, law and social, community and government services” – 43 is assisting occupations in education and legal and public protection, 44 includes home care providers, 45 is crossing guards. Each of these are represented by only a small number of jobs in the database. In the case of NOC 43, Workforce people tell me these are mostly firefighters in Windsor and they have excellent benefits, but there are no firefighter jobs on offer in this data set. That NOC is represented by two jobs for casual teaching assistants.
Not as clean but perhaps more useful – here’s the benefits data summarized by Workforce sector code, which are collections of one to four two-digit NAICS codes. “NAICS” is the North American Industry Classification System.
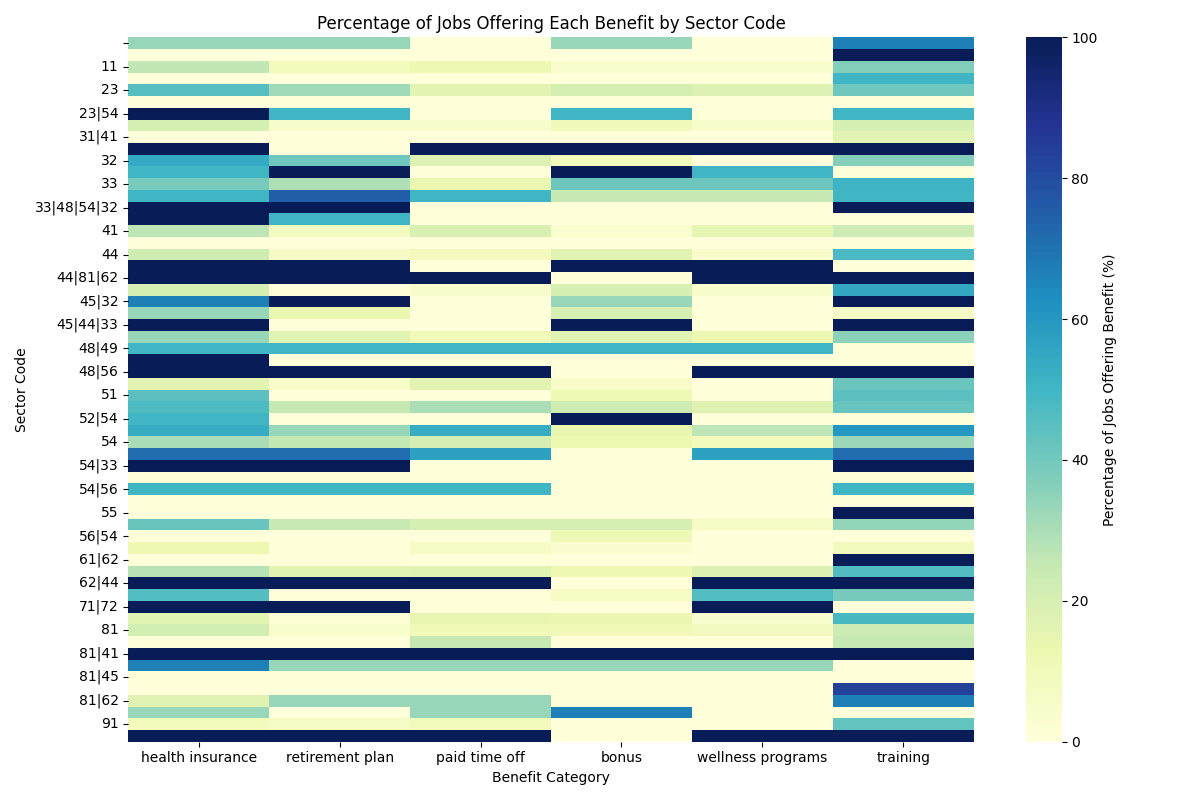
In this case, Workforce adds value to their jobs data by creating a precise sectoral profile for each employer. If a company does engineering for the construction industry, they get assigned a sector code for both construction and engineering.
I would caution against drawing hard conclusions from this data no matter what, because of the limited maturity of the proof-of-concept, but the main problem is that we’re working with a subset of a snapshot of jobs data from a particular point-in-time. It’s a subset because of data ingestion problems with one particular job board. I’m hoping to assemble a bigger collection of jobs in the future to get a clearer picture of this data.
Anyway, that’s the work I did. I came away from it convinced that LLMs can be a valuable tool for data analysts in helping to extract meaning quickly and cheaply from unstructured data. I’m pretty excited to use this technique in my data projects moving forward.
10 episodes



